CMU 15-445 P1&P2 支持并发的缓存池及B+树索引
写掉了CMU 15-445 (2024fall) 课程的Project #1#2,记录一些学到的东西以及还未实现的优化。
P1 缓存池
缓存池存在于内存中,用于缓存并管理磁盘中数据库文件的一部分页
缓存池的主要作用:
- 将常用的页存储在缓存中,减少访问时产生的磁盘I/O次数
- 同样地,缓存池也可缓存用户的更新,我们在对数据库中的数据修改时并不直接对磁盘文件进行操作,而是先缓存在内存中,等到需要写回时再写回
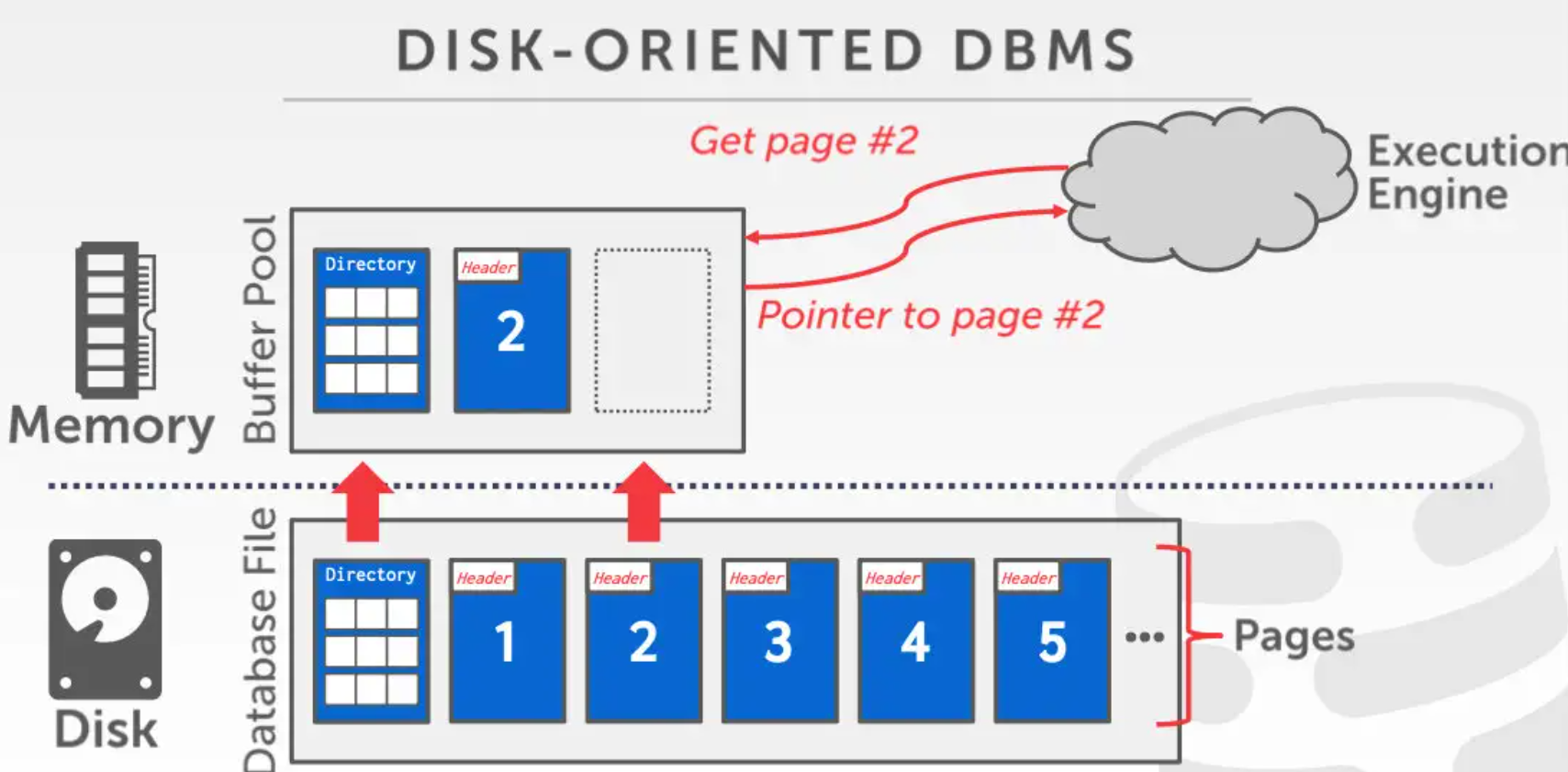
缓存池由连续的frame构成,每个frame 存放一个页的数据以及一些元信息。
替换策略
对于一个缓存池,它的优秀程度很大一部分程度上由其替换策略决定。常见的缓存策略有LIFO,FIFO,LRU,LRU-K。本次实现的缓存池使用了lru-k 策略,即优先驱逐最近第k次访问时间最久的页,其优势在于能较好地避免偶发性的数据被缓存(类似连续扫描访问),从而提高缓存命中率。
对于缓存池的替换策略的优化,lecture中还提到了如下几种:
- priority-hint 在访问的同时给出重要性指标,重要性越高的数据越靠后清除
- 脏页处理 对于进入缓存池后没有被修改过的页,我们不需要写回磁盘直接驱逐。我们也可以进行异步写回处理,周期性的集中写回缓存池中所有脏页。但是需要注意这种操作会引起断电时数据错误。
缓存池优化
- 对于数据库中常见的一类操作连续扫描,我们可以在访问的同时给出操作特征。对于周期扫描访问到的页,可以让其不进入缓存池直接写回,或是进行优先写回标记
- 我们可以同时使用多个缓存池,来保存不同类型的数据,如索引页,元数据,一般数据。不同类型的数据访问频率差异很大,可以分配不同的缓存池大小,使用不同的替换策列。同时多缓存池也可提高并发效率(减少等待bpm锁的时间)。
- 操作系统在进行磁盘I/O的时候也会开一个缓存空间,但是其效率往往很差。因此我们在操作系统提供的读写api中加入
O-DIRECT参数来直接I/O
并发控制
在缓存池运行的过程中,参与的数据可分为两类,缓存池拥有的和页拥有的。因此在并发控制时,我们对bpm和frame分别设计一把锁。Project 1 的一个难点就是处理这两种锁的交互关系。
在请求访问一个页以及结束访问时,我们的操作过程是:
在bpm中查询修改,标记页被占用->获取frame的数据所有权->释放frame的数据所有权->在bpm中查询修改,标记页结束占用
由此可见在这个过程中我们会持续持有frame的锁一段时间,而bpm的锁只需要在请求和释放时锁住即可。这里有一个很容易引发死锁的点,是我们必须先结束修改bpm(并释放锁),再获取frame的数据所有权(锁),在释放时,也应按照完全对称的方式进行。
1 | 考虑此情况 线程T0 线程T1 |
思考为何这种模式引发死锁:在设计时,我们并没有要求“只有bpm的所有者可以拥有frame的读写权”,实际上,我们只需要保证frame在bpm中的信息始终是正确的即可。这只需要我们在获取frame所有权之前修改好bpm,释放bpm锁后其他进程可以插队请求其他的frame读写权,但是由于bpm中当前frame的信息已经被更新为占用,不会产生冲突。
P2 B+树
B+树是一种M-way的平衡树。它的一个特点是所有数据都存储在叶子节点中,内部节点只存放标识键和指针。B+树相当适合作为数据库索引。它的优势有
- 增删查的时间复杂度都为 O ( log n ),相比于块状链表等单层索引优秀很多
- 支持高效范围查找(相比于哈希表,其他平衡树)
- 数据存放集中,可以通过设计使得每个节点的大小都为刚好一个页存储量,对磁盘I/O友好
- …
通过合理设计索引,B+树可以支持联合索引,查询满足若干个关键词的数据 (在TicketSystem的文件存储测试部分实际上已经用到了)
RAII
2024fall 版本的bustub 采用了使用 RAII(Resource Acquisition Is Initialization)思想设计的 PageGuard 类。写的过程中发现它相当好用,几乎完全避免了在B+树层面考虑并发控制。 之前只是知道用 RAII 设计封装好的一些类,如智能指针。这次学到了如何用一个 RAII 的类来简化程序设计。
简单地说,在我们申请 PageGuard 的同时,我们获取了对这个 page 在 bpm 中对应 frame 的读写权,即获取 frame 锁,在 PageGuard 对象超出作用域自然销毁的时候,我们释放 frame 锁,更新 bpm 信息。
这么做的好处其实就是避免人为决定何时释放锁。通过系统对栈的自动管理,我们让资源管理的实际行为和我们的设计预期相符:需要用的时候是锁住的,不需要用的时候会立刻释放。
优化
- 并发控制优化 对并发的优化实则就在于尽可能少锁住树的节点。在 naive 的实现中,我们每次操作都锁住从根节点到对应叶节点的一串节点,再到达叶节点后再从下往上解锁(即 crabbing)。一个容易想到的优化就是,当我们发现当前节点未来不会发生改变(分裂或合并),我们直接释放掉到当前节点为止的所有锁。我在查询中实现了这个优化,但增和删都未实现,最后的 qps 差距也是非常的大。
- 并发控制优化其二:乐观锁 实际上绝大部分增删操作不会引起分裂或合并,因此我们在一开始只上读锁,如果最后访问到叶子节点时发现其需要进行分裂合并,我们再从根节点开始重新上一遍写锁。
- 节点内部查询 由于B+树所有节点内部键均有序,我们可以使用二分查找。但这部分在数据库中整体时间消耗占比实际上比较少。
- B+树的参数选择 对于越快的存储设备,节点大小应该越小,从而减少读写冗余的数据。对于点查找比范围查找更少的负载类型,节点大小应该更大,这样读写叶子节点的次数会更少。

- 调节合并操作的阈值。我们并不一定需要当节点一达到半满就合并,有的时候可以允许小于半满的节点存在。
- 前缀压缩和去重 我们可以记录同一个叶子节点中键的共同前缀,或者直接将一个 key 对应多个 value 来压缩空间
- 磁盘空间回收 其实就是在磁盘管理的时候改成存一下哪块地方的数据已经不要用了。在bustub 中
page_id直接对应磁盘上的一个位置。如果要改的话应当在disk_manager中再加一个map对应一下page_id和实际位置,用一个小根堆维护下一个可用位置,对于不要省磁盘空间的情况其实影响不太大。